Top Albums and Runtime with Web Scraping#
This project was very open ended; we had to think of a question that we could solve through web scraping data.
My question was related to my interests in the music world, friends of mine always said “short pop songs are all that matter” so I wanted to see if album run time varied across the hit albums of the last few years.
This was a fantastic exercise in actually understanding how data scientists might collect data but also how much is needed to come to a real conclusion, my analysis was good but it was clear I need another piece to this story, data that would show what the average album runtime was to compare.
It’s also interesting because Taylor swift dominated the charts and had relatively long albums, but that doesn’t mean we should assume she’s popular from this alone as there are obviously other factors in play.
A more interesting route would be to see if upcoming stars and groups tend to release longer or shorter albums.
Question: Does album run time have anything to do with being a top selling album in a year?#
import requests
from bs4 import BeautifulSoup
import pandas as pd
import seaborn as sns
This is a link to the starting wiki: albums
The bs4 object#
After first retreaving and parsing the html I explored the websit using inspect and found ‘tbody’ was holding the lists of names and links. All the links to the individual albums were wrapped in i tags, using “.a” so we isolate the individual links and names.
albums_url = 'https://en.wikipedia.org/wiki/Top_Album_Sales#2020'
albums_html = requests.get(albums_url).content
cs_albums = BeautifulSoup(albums_html, 'html.parser')
type(cs_albums)
bs4.BeautifulSoup
wiki_content = cs_albums.find_all('tbody')
wiki_content[1].find_all('i')
[<i><a class="mw-redirect" href="/wiki/1989_(Taylor_Swift_album)" title="1989 (Taylor Swift album)">1989</a></i>,
<i><a href="/wiki/2014_Forest_Hills_Drive" title="2014 Forest Hills Drive">2014 Forest Hills Drive</a></i>]
wiki_content[1].find('i').a
<a class="mw-redirect" href="/wiki/1989_(Taylor_Swift_album)" title="1989 (Taylor Swift album)">1989</a>
wiki_content[1].find('i').a.string
'1989'
Getting consistency#
Searching trhrough tags we can scrape a single name, now we can apply this to the entire wiki_content. I define a start to the url since its not included in the href to construct working url’s. The next step was isolating the runtime and year released from the constructed link, then applying the method to everything.
album_names = [i.a.string for i in wiki_content[1].find_all('i')]
album_names
['1989', '2014 Forest Hills Drive']
album_names = [i.a.string for name in wiki_content
for i in name.find_all('i')
if i.a and i.a.string]
wiki_content[1].find('i').a
<a class="mw-redirect" href="/wiki/1989_(Taylor_Swift_album)" title="1989 (Taylor Swift album)">1989</a>
wiki_content[1].find('i').a['href']
'/wiki/1989_(Taylor_Swift_album)'
url_start = "https://en.wikipedia.org"
test_url = url_start + wiki_content[1].find('i').a['href']
test_url
'https://en.wikipedia.org/wiki/1989_(Taylor_Swift_album)'
Getting the runtime and year released from the constructed link#
test_html = requests.get(test_url).content
test_info = BeautifulSoup(test_html,'html.parser')
test_info.find('span', class_="min")
<span class="min">48</span>
test_min = test_info.find('span', class_="min").string
test_min = int(test_min.strip())
test_min
48
test_info.find('span', class_='bday dtstart published updated itvstart').string
'2014-10-27'
test_date = test_info.find('span', class_='bday dtstart published updated itvstart').string
test_date
'2014-10-27'
test_year = test_date.split('-')[0]
test_year
'2014'
Method to construct Links#
album_links = [url_start + i.a['href']
for link in wiki_content
for i in link.find_all('i')
if i.a and 'href' in i.a.attrs]
album_links[1]
'https://en.wikipedia.org/wiki/2014_Forest_Hills_Drive'
After finding out how to extract the run time I use a loop to do requests through all associated links#
album_years = []
run_time = []
time_size = []
I also added a time_size catagory to help group by times
for test_url in album_links:
test_html = requests.get(test_url).content
test_info = BeautifulSoup(test_html,'html.parser')
try:
test_min = test_info.find('span', class_="min").string
test_date = test_info.find('span', class_='bday dtstart published updated itvstart').string
test_year = test_date.split('-')[0]
test_year = int(test_year.strip())
album_years.append(test_year)
test_min = int(test_min.strip())
run_time.append(test_min)
if test_min < 20:
time_size.append('Very Short')
elif test_min >= 20 and test_min < 35:
time_size.append('Short')
elif test_min >= 35 and test_min < 60:
time_size.append('Average')
elif test_min >= 60:
time_size.append('Long')
else:
time_size.append(pd.NA)
except:
run_time.append(pd.NA)
time_size.append(pd.NA)
album_years.append(pd.NA)
albums_df = pd.DataFrame({'Album Name':album_names, 'Release Year':album_years, 'Length Rating':time_size, 'Run-Time(Mins)':run_time,'links':album_links})
albums_df
| Album Name | Release Year | Length Rating | Run-Time(Mins) | links | |
|---|---|---|---|---|---|
| 0 | 1989 | 2014 | Average | 48 | https://en.wikipedia.org/wiki/1989_(Taylor_Swi... |
| 1 | 2014 Forest Hills Drive | 2014 | Long | 64 | https://en.wikipedia.org/wiki/2014_Forest_Hill... |
| 2 | 1989 | 2014 | Average | 48 | https://en.wikipedia.org/wiki/1989_(Taylor_Swi... |
| 3 | Title | 2015 | Short | 32 | https://en.wikipedia.org/wiki/Title_(album) |
| 4 | American Beauty/American Psycho | <NA> | <NA> | <NA> | https://en.wikipedia.org/wiki/American_Beauty/... |
| ... | ... | ... | ... | ... | ... |
| 444 | Billboard Philippines | <NA> | <NA> | <NA> | https://en.wikipedia.org/wiki/Billboard_Philip... |
| 445 | Billboard Türkiye | <NA> | <NA> | <NA> | https://en.wikipedia.org/wiki/Billboard_T%C3%B... |
| 446 | Billboard Việt Nam | <NA> | <NA> | <NA> | https://en.wikipedia.org/wiki/Billboard_Vi%E1%... |
| 447 | Music & Media | <NA> | <NA> | <NA> | https://en.wikipedia.org/wiki/Music_%26_Media |
| 448 | Billboard Radio Monitor | <NA> | <NA> | <NA> | https://en.wikipedia.org/wiki/Billboard_Radio_... |
449 rows × 5 columns
I start cleaning my data br removing all na’s and duplicates#
albums_clean_df = albums_df.dropna()
albums_clean_df.describe()
| Album Name | Release Year | Length Rating | Run-Time(Mins) | links | |
|---|---|---|---|---|---|
| count | 355 | 355 | 355 | 355 | 355 |
| unique | 302 | 14 | 4 | 79 | 303 |
| top | A Star Is Born | 2017 | Average | 48 | https://en.wikipedia.org/wiki/A_Star_Is_Born_(... |
| freq | 8 | 47 | 203 | 18 | 8 |
albums_clean_df =albums_clean_df.drop_duplicates()
albums_clean_df
| Album Name | Release Year | Length Rating | Run-Time(Mins) | links | |
|---|---|---|---|---|---|
| 0 | 1989 | 2014 | Average | 48 | https://en.wikipedia.org/wiki/1989_(Taylor_Swi... |
| 1 | 2014 Forest Hills Drive | 2014 | Long | 64 | https://en.wikipedia.org/wiki/2014_Forest_Hill... |
| 3 | Title | 2015 | Short | 32 | https://en.wikipedia.org/wiki/Title_(album) |
| 6 | Now 53 | 2015 | Long | 74 | https://en.wikipedia.org/wiki/Now_That%27s_Wha... |
| 7 | If You're Reading This It's Too Late | 2015 | Long | 68 | https://en.wikipedia.org/wiki/If_You%27re_Read... |
| ... | ... | ... | ... | ... | ... |
| 428 | F-1 Trillion | 2024 | Average | 57 | https://en.wikipedia.org/wiki/F-1_Trillion |
| 429 | Days Before Rodeo | 2014 | Average | 50 | https://en.wikipedia.org/wiki/Days_Before_Rodeo |
| 430 | Crazy | 2024 | Very Short | 14 | https://en.wikipedia.org/wiki/Crazy_(Le_Sseraf... |
| 431 | Luck and Strange | 2024 | Average | 43 | https://en.wikipedia.org/wiki/Luck_and_Strange |
| 433 | The Rise and Fall of a Midwest Princess | 2023 | Average | 49 | https://en.wikipedia.org/wiki/The_Rise_and_Fal... |
304 rows × 5 columns
albums_clean_df.describe()
| Album Name | Release Year | Length Rating | Run-Time(Mins) | links | |
|---|---|---|---|---|---|
| count | 304 | 304 | 304 | 304 | 304 |
| unique | 302 | 14 | 4 | 79 | 303 |
| top | The Album | 2017 | Average | 41 | https://en.wikipedia.org/wiki/Face_the_Sun |
| freq | 2 | 42 | 179 | 16 | 2 |
Removing irrelevant Data#
I noticed we really only get relevant data from starting from 2015, theres not much to comapir from 2014 since only 4 albums are listed and the years below that seem to be dummy variables.
albums_clean_df['Release Year'].value_counts()
Release Year
2017 42
2016 34
2020 34
2019 31
2021 30
2023 30
2018 29
2015 28
2022 20
2024 19
2014 4
2001 1
1967 1
1969 1
Name: count, dtype: int64
albums_clean_df = albums_clean_df[albums_clean_df['Release Year'] >= 2015]
albums_clean_df['Release Year'].value_counts()
Release Year
2017 42
2016 34
2020 34
2019 31
2021 30
2023 30
2018 29
2015 28
2022 20
2024 19
Name: count, dtype: int64
albums_clean_df['Length Rating'].value_counts()
Length Rating
Average 175
Long 69
Short 38
Very Short 15
Name: count, dtype: int64
albums_clean_df['Run-Time(Mins)'].mean()
50.51851851851852
albums_clean_df.groupby('Length Rating')['Run-Time(Mins)'].mean()
Length Rating
Average 45.56
Long 83.057971
Short 28.052632
Very Short 15.6
Name: Run-Time(Mins), dtype: object
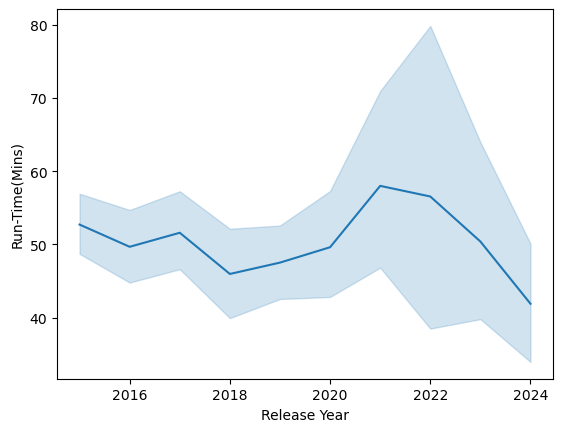
sns.lineplot(data=albums_clean_df,x='Release Year', y='Run-Time(Mins)')
<Axes: xlabel='Release Year', ylabel='Run-Time(Mins)'>
sns.catplot(data=albums_clean_df,x='Release Year', y='Run-Time(Mins)',kind='bar', hue='Length Rating')
<seaborn.axisgrid.FacetGrid at 0x1a0ea0538f0>
Summary#
Overall, top chart albums stay around 45 minutes. If we combine counts of small ,very small, and long albums we come to 122 which is still lower than average at 175. I would say this leads to inconclusive data, if anything this may say more about the amount of work the music indusry puts into projects. Removing duplicates was useful but It would be more useful to observe months in the year to see if theres any dominating artists that write longer or shorter albums.
albums_clean_df.to_csv('Album_Runtime.csv', index=False)